
In this section, we describe how we create our dataset and provide case studies to interpret the data.
Twitter Panel
Table of Contents
Our dataset is based on a panel of over 1.5 million registered U.S. voters on Twitter, created by our team in previous work. A pilot version of the panel was first used by Grinberg et al.38then the panel was expanded considerably by Shugars et al.20 and validated by Hughes et al.39 To create the panel, we start with the Twitter Decahose, a 10% random sample of all tweets, and identify 290 million accounts that post content between January 2014 and March 2017. We extract the names of the users, either from the Twitter handles or display names, and their location from the account profiles. This information is then matched against voter data provided by TargetSmart in October 2017, covering all 50 U.S. states and the District of Columbia. We compare the full name of each person in the voter file with the names of the Twitter accounts. If the full name has fewer than 10 exact matches, we then examine the location of the Twitter accounts. A Twitter account and voter record pair is accepted only if that is the only person in the specified city or state-level geographic area in both datasets. This reliance on full names and disclosed locations helps to eliminate many fake, automated (bot), and organizational accounts.
The data collection and matching of Twitter panel were approved by the Northeastern University Institutional Review Board (protocol number: 17-12-13). Following the best practices outlined by Hemphill et al.40we employ data aggregation, anonymization, and access control measures to protect user privacy and minimize the risk of re-identification in our Twitter panel.
Matching to voter file records provides access to the geolocation, year of birth, gender, race/ethnicity, and partisanship of the users in the panel. We use state-level geolocation data from the voter files as our geographic unit of analysis. While we have access to more detailed location information, such as county-level data, releasing this information would risk re-identifying the users due to the low population density of many U.S. counties. State-level granularity offers a good compromise between the usefulness of the data and the privacy of the users. Using the year of birth, we determine the age of users at the time of sharing events and categorize them into the following age groups: “<18,” “18-29,” “30-49,” “50-64,” and “65+.” The category for users younger than 18 years old is included because some states allow 17-year-olds to pre-register to vote and some users might be younger than 18 at the time of sharing events. Gender is a binary measure provided by TargetSmart, which does not capture gender identities beyond the binary framework41. Race/ethnicity information is inferred by TargetSmart for most states and is categorized as “African-American,” “Asian,” “Hispanic,” and “Caucasian.” Other race categories with limited representation in the dataset are aggregated into a single “Other” category to minimize re-identification risks.
TargetSmart provides two measures of partisanship: party registration and inferred partisanship. Party registration information in voter files is self-reported and aligns well with survey self-reporting42. However, this information is unavailable for 20 states (AL, AR, GA, HI, IL, IN, MI, MN, MO, MS, MT, ND, OH, SC, TN, TX, VA, VT, WA, and WI) in the TargetSmart data, which account for 42.7% of the Twitter users in our panel. When categorizing party registration information, we treat values for users in the 20 aforementioned states as missing. For the other 30 states and the District of Columbia, users registered as “Democrat” and “Republican” are coded accordingly. Due to variations in the classification of independent registered voters by state, we group individuals listed as “Independent,” “No party,” or “Unaffiliated” into a single “Independent” category. Members of minor parties, such as the Green Party and the Libertarian Party, are categorized as “Other.”
Based on party registration and other indicators, TargetSmart infers the probability of all individuals in all 50 states and the District of Columbia voting Democrat. We categorize individuals as Republican (0-0.35), Independent (0.35-0.65), and Democrat (0.65-1) using TargetSmart’s recommended thresholds to generate the inferred partisanship. For our data release and analysis, we use inferred partisanship as the primary measure since it covers all users (referred to as “party” hereafter). Additionally, we provide party registration information as a secondary measure (referred to as “party registration” or “partyreg” hereafter), as it conveys a slightly different signal and offers useful insights for certain analyses.
Missing values in all dimensions are coded as “Unknown.”
Domain-sharing Statistics
We collect posts from users in the panel spanning from May 2011 to April 2022. We extract the links shared by these users, expand the shortened links when possible, and identify the corresponding domains (e.g., nytimes.com for The New York Times). This process allows us to determine which user shares what domains and when. Sharing events, as defined in our study, include posting links in original tweets and retweeting or quoting tweets containing links. To reduce noise and the risks of re-identification, we include only domains that are shared by at least 50 unique users throughout the entire period.
We integrate the demographic information of users with their domain-sharing records to construct a comprehensive table. This domain-sharing event table includes the following columns: user_id, domain, age, gender, race, party, party registration, state, and year-month. Each row corresponds to a single sharing event, with users who share the same domains multiple times contributing multiple rows. Due to the presence of user identifiers, we cannot release this detailed table. Instead, we provide aggregate statistics derived from this table including DomainDemo-multivariate and DomainDemo-univariate.
DomainDemo-multivariate describes the domain sharing behavior of users across different demographic dimensions simultaneously. It includes several variants designed to facilitate different types of research analyses. The most granular variant is the monthly distribution data at the domain level, which is produced by grouping the domain-sharing event table by domain, age, gender, race, party (party registration is excluded here), state, and year-month. In each bucket, we calculate the following statistics: the number of shares, the number of unique users who share the domain, and the Gini index of the sharing count across users. Formally, the Gini index G for a domain is calculated as:
$$G=frac{1}{2{N}^{2}bar{x}}mathop{sum }limits_{i=1}^{N}mathop{sum }limits_{j=1}^{N}|{x}_{i}-{x}_{j}|,$$
(1)
where N is the number of users who share the domain, xa is the number of shares by the a-th user, and (bar{x}={sum }_{i=1,}^{N}{x}_{i}/N) is the average number of shares per user. G ranges from 0 to 1, with 0 indicating equal sharing and values close to 1 indicating that a few users share the domain disproportionately. Note that we set the Gini index to 1 for domains shared by only one user in the bucket. We include the Gini index to help researchers understand the inequality of sharing events across users without releasing detailed information about these users due to privacy concerns.
In addition to the demographic distribution of users sharing each domain, it is useful to understand the distribution of the whole population in many cases. Therefore, we also include a “baseline” variant that group the the domain-sharing event table by age, gender, race, party, state, and year-month. In each bucket, we calculate the same statistics as the monthly distribution data. We also provide the average number of unique domains shared by users in each demographic bucket and the corresponding standard deviation. On top of the monthly data, we further provide the distribution and baseline data covering the whole time period. In total, DomainDemo-multivariate includes four variants.
DomainDemo-univariate is generated by aggregating the sharing events across all demographic dimensions except for the one of interest. For example, the state univariate data (referred to as the “state universe”) is produced by aggregating the sharing events across all age, gender, race, and party dimensions, resulting in the statistics of sharing events within different states. In each bucket of DomainDemo-univariate, we provide three statistics: the number of shares, the number of unique users who share the domain, and the Gini index of the sharing count across users. And similar to DomainDemo-multivariate, DomainDemo-univariate includes four variants: monthly distribution, monthly baseline, all-time distribution, and all-time baseline.
The detailed data schema of the released versions of DomainDemo-multivariate and DomainDemo-univariate can be found in the Data Records section.
Derived Metrics for Domains
Based on the sharing behavior of users in different demographic groups, we derive additional metrics that quantify different aspects of the domains.
Domain Localness Metric
Local news is a fundamental component of the U.S. democratic process. It is uniquely positioned to report on local affairs and elections, enabling citizens to engage in local political activities and hold their elected officials accountable31,32. However, the landscape of local journalism is undergoing significant changes, marked by a notable decline in local agencies, often referred to as the emergence of the “news desert”33,34. This trend threatens the vibrancy of local political participation and raises concerns about the overall health of democracy43,44.
To empirically understand the dynamics of news consumption and related phenomena, it is essential to reliably categorize news outlets as either local or national. Despite extensive research efforts, a universally accepted definition of local news organizations remains elusive45. Many studies on local news often fail to provide a clear definition or specific criteria for classification46complicating efforts to expand the scope of classification and hindering the replication of analyses.
Here, we leverage the state universe data from DomainDemo-univariate to derive a data-driven metric that quantifies the “localness” of news domains. This is achieved by calculating the deviation of the user distribution of each domain in different states from the baseline distribution, both of which are provided in DomainDemo-univariate.
For a formal definition, let Cs represent the number of unique users in state s across all domains, and Fs represent the corresponding frequency, where Fs = Cs/∑sCs. Fs characterizes the baseline distribution of the whole population. For a domain dwe calculate the user frequency in state s, Fd,s = Cd,s/∑sCd,swhere Cd,s represents the number of unique users in state s who share the domain d. For domains shared by diverse users, the observed distribution Fd,s should closely align with the baseline distribution Fs across different states. However, deviations from the baseline distribution are expected for domains with a more concentrated audience.
Following this intuition, we quantify the deviation of a domain, denoted by ({}using the Kullback-Leibler (KL) divergence between Fd,s and Fs:
$${{mathcal{L}}}_{delta }={D}^{(KL)}({F}_{delta ,s}| | {F}_{s})=sum _{s}{F}_{delta ,s}{log }_{2}frac{{F}_{delta ,s}}{{F}_{s}},$$
(2)
where ({F}_{delta ,s}{log }_{2}({F}_{delta ,s}/{F}_{s})) measures the discrepancies between the observed sharing patterns and the baseline distribution of domain d in state s. ({} is a non-negative value that is minimized at zero when Fd,s and Fs are identical. In other words, national news domains should have ({} close to zero, while local news domains should have bigger ({} values. In the Technical Validation section, we show that ({} is a good proxy for the localness of news domains.
A limitation of ({} is that it can only indicate the deviation of a domain’s sharing pattern from the baseline distribution. To reveal which states are over-represented or under-represented, one needs to further inspect the values of Fd,s and Fs.
Domain Audience Partisanship Metric
A healthy democratic society requires the public to receive accurate and unbiased news and civic information, especially during election seasons47. However, the presence of partisan online news and phenomena such as echo chambers and filter bubbles remain concerns35,48. To address these issues, researchers have investigated the political biases embedded in online platforms, including search engines like Google49 and social media platforms like Facebook35Twitter50and YouTube51. Other relevant research has focused on how users interact with different information sources and their consumption patterns36,52,53. Such analyses generally involve assessing the political leanings of numerous domains, but such datasets have been rare and often lack comprehensive coverage (see discussion in the Technical Validation section).
Here, we employ the party (and party registration) universe data from DomainDemo-univariate to create data-driven metrics that assess the audience partisanship of domains. We focus on Democrat and Republican and exclude Independent users. The number of users from each party allows us to quantify the partisanship of the audience for each domain. It is important to note that our audience-based metrics do not evaluate the content characteristics of these domains. However, previous research indicates that audience characteristics are closely associated with the leanings of these domains54,55.
Formally, the audience partisanship score ({{mathcal{P}}}_{delta }) of a domain d is calculated as follows:
$${{mathcal{P}}}_{delta }=frac{frac{{C}_{delta ,r}}{{C}_{r}}-frac{{C}_{delta ,d}}{{C}_{d}}}{frac{{C}_{delta ,r}}{{C}_{r}}+frac{{C}_{delta ,d}}{{C}_{d}}},$$
(3)
where Cd,r and Cd,d (available in the distribution variant of DomainDemo-univariate) represent the number of unique users from the Republican and Democrat parties who share the domain drespectively. Cr and Cd (available in the baseline variant of DomainDemo-univariate) represent the total number of unique users in the Republican and Democrat parties who share any domain, respectively. Since a user can share multiple domains, we have Cd,r ≤ Cr ≤ ∑iCi,r and Cd,d ≤ Cd ≤ ∑iCi,d. ({{mathcal{P}}}_{delta }) is a continuous value between −1 and +1, where −1 means the domain d is exclusively shared by Democratic users and +1 means d is exclusively shared by Republican users.
Other Metrics
In addition to the localness and audience partisanship metrics, we release three more audience-based metrics: age deviation, race deviation, and gender leaning, to help researchers understand the sharing patterns conditioned on these demographic variables. The age and race deviation metrics are calculated using Eq. (2), where the state categories are replaced with the age or race categories. These metrics quantify how concentrated the audience is in certain age or race groups. The gender leaning metric is calculated using Eq. (3), where the party categories are replaced with the gender categories. Similar to the audience partisanship metric, the gender leaning metric is also a continuous value between −1 and +1, where −1 means the domain is exclusively shared by male users and +1 means the domain is exclusively shared by female users.
The calculation of these metrics is very flexible. While we primarily use the unique number of users in both Eqs. (2) and (3), our experiments demonstrate that using the number of shares produces highly correlated results. The metrics can also be calculated over different time periods. In this paper, we present results for the entire time period in the released version, case studies, and validation. To facilitate reproducibility and customization, we provide the code for calculating these metrics, allowing readers to modify the formulas according to their specific needs.
Our formulas in Eqs. (2) and (3) have a limitation: they rely solely on user distribution without accounting for variations in sharing patterns across demographic groups. For example, our analysis reveals that Democratic users share more diverse domains than Republican users, averaging 74.9 unique domains compared to 54.5 across the whole period. To enable researchers to develop more sophisticated metrics that incorporate these behavioral differences, we provide the mean number of unique domains shared by users in each demographic category and the corresponding standard deviations in the baseline variants of our datasets.
Case Studies
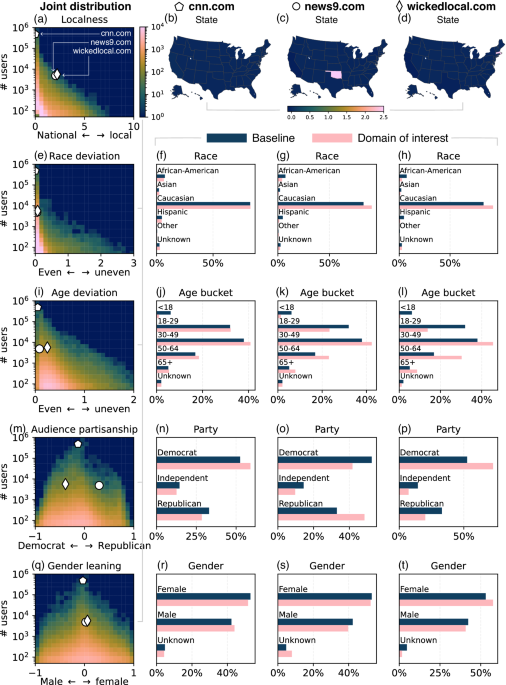
To help the readers interpret the derived metrics, we present the distributions for all domains in the dataset and provide case studies for three example domains in Fig. 1.
Distributions of the derived metrics for all domains, along with detailed information for three domains: cnn.com, news9.comand wickedlocal.com. The left column presents the joint distributions of our derived metrics and the unique number of users who share each domain across the entire dataset. The color coding represents the number of domains within each grid cell. The symbols indicate the locations of the three domains. The three columns on the right provide detailed distributions of users in various demographic dimensions for the three domains respectively. Sub-figures (b–d) highlight the discrepancies between the observed user distribution and the baseline distribution across U.S. states for the three domains. The color coding indicates the ({F}_{delta ,s}{log }_{2}({F}_{delta ,s}/{F}_{s})) value in each state. The bar plots display both the baseline distribution and the distribution of users in each demographic category for the domain of interest. The baseline distribution represents the patterns observed across all domains in the dataset.
Firstly, cnn.coma national news outlet, has a user base closely aligned with the baseline. Consequently, its localness ( ({{ mathcal {l}}} _ { delta} = 0.013 )), race deviation ( ({{ mathcal {l}}} _ { deta} = 0.002)), age deviation ( ({{ mathcal {l}}} _ { delta} = 0.049 )), and gender leaning (({{mathcal{P}}}_{delta }=-,0.033)) scores are near zero. cnn.com is shared more often by Democratic users and less often by Republican users than the baseline, resulting in an audience partisanship score of −0.132.
The second example, news9.comis a local news outlet in Oklahoma City, Oklahoma. It is shared by fewer users than cnn.com and has a localness score of 2.072, indicating a localized audience. Figure 1(c) shows that news9.com is over-represented in Oklahoma, confirming its local nature. Additionally, news9.com is shared more often by Republican users and less often by Democratic users compared to the baseline, leading to an audience partisanship score of 0.297. Its user base has race ( ({{ mathcal {l}}} _ { delta} = 0.051 )) and gender (({{mathcal{P}}}_{delta }=0.026)) profiles similar to the baseline but is shared more often by older users ( ({{ mathcal {l}}} _ { delta} = 0.086 )).
The third example is wickedlocal.coma local news source in Boston, Massachusetts. Figure 1(d) indicates that it is over-represented in Massachusetts, consistent with its localness score of 2.221. Unlike news9.com, wickedlocal.com is shared more often by Democratic users (({{mathcal{P}}}_{delta }=-0.387)) and even more often by older users ( ({{ mathcal {l}}} _ { delta} = 0.246)). Otherwise, the user base of wickedlocal.com has a similar profile in terms of race ( ({{ mathcal {l}}} _ { delta} = 0.071 )) and gender (({{mathcal{P}}}_{delta }=0.060)) to that of news9.com.
Due to space constraints, we can only provide three case studies here. We have released an interactive app to allow readers to explore the patterns of other domains in our dataset at domaindemo.info.